A modern, automated pipeline for clean, reliable, intent-driven keyword research.
Traditional keyword research is slow, messy, and often unreliable. You gather lists from different tools, merge spreadsheets, fight endless duplicates, and hope that third-party metrics are at least somewhat close to reality. And after all that work, you still end up with a dataset that’s too noisy to confidently plan your content or paid campaigns.
To fix this problem end-to-end, I built the Automated Keyword Selection and Cluster Mapping Service (AKSCMS) — a fully automated pipeline that transforms scattered keyword inputs into a clean, structured, high-fidelity semantic map.
This system is powered by:
The result is a dataset that is both technically uncompromising and incredibly easy to use in real-world SEO and advertising workflows.

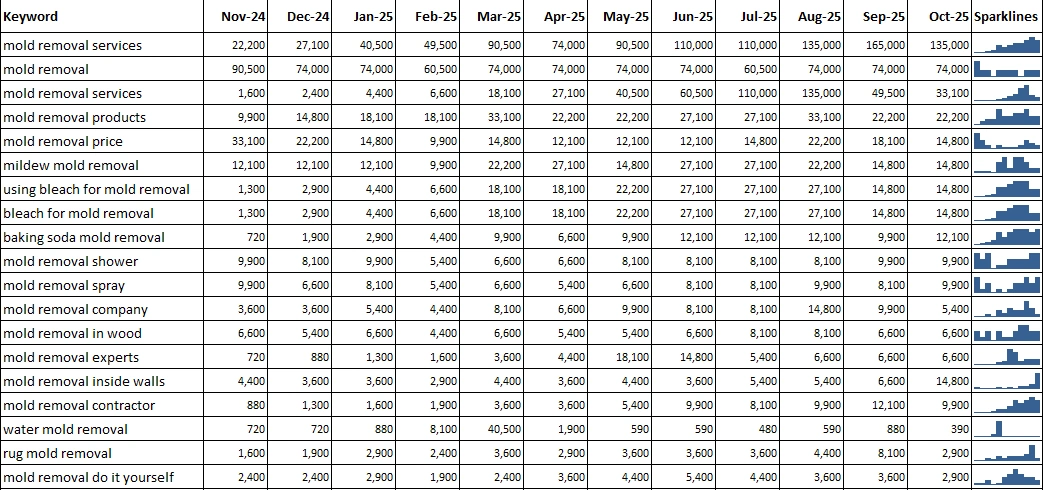
Upload a sample: Keyword Research for a Mold Remediation Contractor
The core objective of the AKSCMS is simple: automate keyword research at an enterprise level while removing all manual inefficiencies.
It combines two types of input signals:
This merged dataset is then enriched directly via the Google Ads Data API.
And this part is crucial: because the system pulls raw, first-party metrics from Google, it eliminates the inaccuracies and delays inherent in all SEO aggregator tools.
You’re not working with “estimated volume” — you’re working with the real thing.
A major part of the pipeline is the proprietary NLP-based normalization and filtering engine.
Its job is to produce a dataset that is:
The NLP module also uses NLTK resources such as stopwords and WordNetLemmatizer. During initialization, the system loads the stopword corpus to filter out non-informative terms and accesses the WordNet lexical database to perform accurate lemmatization. This ensures consistent normalization of keyword variations and reduces noise caused by morphological differences.
The system applies three strict filters:
This is where the heavy NLP work happens:
This ensures that every keyword in the final dataset represents a unique meaning and a unique search intent — solving content cannibalization before it starts.
Not all clusters are equally valuable. That’s why the final report ranks them based on a composite score that includes:
This converts the dataset from a simple keyword list into a strategic roadmap — showing which content areas can deliver the fastest impact.
The final keyword research package contains data points that typical SEO tools cannot provide reliably.
This provides:
The system flags keywords that indicate emerging demand:
These identify opportunities competitors haven’t seen yet.
The AKSCMS is not a scraper, not a wrapper around an SEO API, and not just another “keyword generator.”
It is a full data-refinement and decision-making engine, with clear advantages:
Marketers, SEOs, CRO specialists, and media buyers can use it to make confident, data-driven decisions without wasting time on manual cleanup or questionable third-party metrics.
This system was built to solve a practical problem: how to generate a high-quality, reliable keyword dataset without the manual pain and without the noise.
The result is a pipeline that delivers:
It replaces chaos with clarity — turning keyword research into a predictable, repeatable, and scalable process.

How do you track the performance of keywords over time?

I use tools like Google Search Console, Ahrefs, and SEMrush to monitor keyword rankings, adjust strategies as needed, and report on progress regularly.
How do you ensure content remains relevant over time?
I regularly update and refresh content to reflect the latest industry trends, keyword opportunities, and user needs, ensuring it remains valuable and ranks well in search engines.
What is your approach to optimizing meta tags?
I write concise, keyword-rich meta titles and descriptions that accurately reflect the page content while also encouraging click-throughs from search results.
How do you manage website migrations to avoid SEO setbacks?
I meticulously plan the migration, including URL mapping, 301 redirects, and thorough testing before and after the migration to ensure a smooth transition without losing search visibility.
How do you measure the success of content in terms of SEO?
I track metrics such as organic traffic, keyword rankings, user engagement, and conversion rates to assess the effectiveness of content from an SEO perspective.

Submit a Request
If you would like to receive any additional information or ask a question, please use this contact form. I will try to respond to you as soon as possible.
Order a Service